Large Scale Computation with HTCondor
Overview
To harness to full abilities of distributed high throughput computing on the OSG, it is necessary to learn how to scale up and control large numbers of jobs. This requires the ability to submit and process multiple jobs in parallel. Examples of workloads that require these considerations include multi-dimensional Monte Carlo integration using sampling, parameter sweep(s) for a given model, and molecular dynamics simulation with several initial conditions. All of these workloads require submitting more than a handful of jobs.
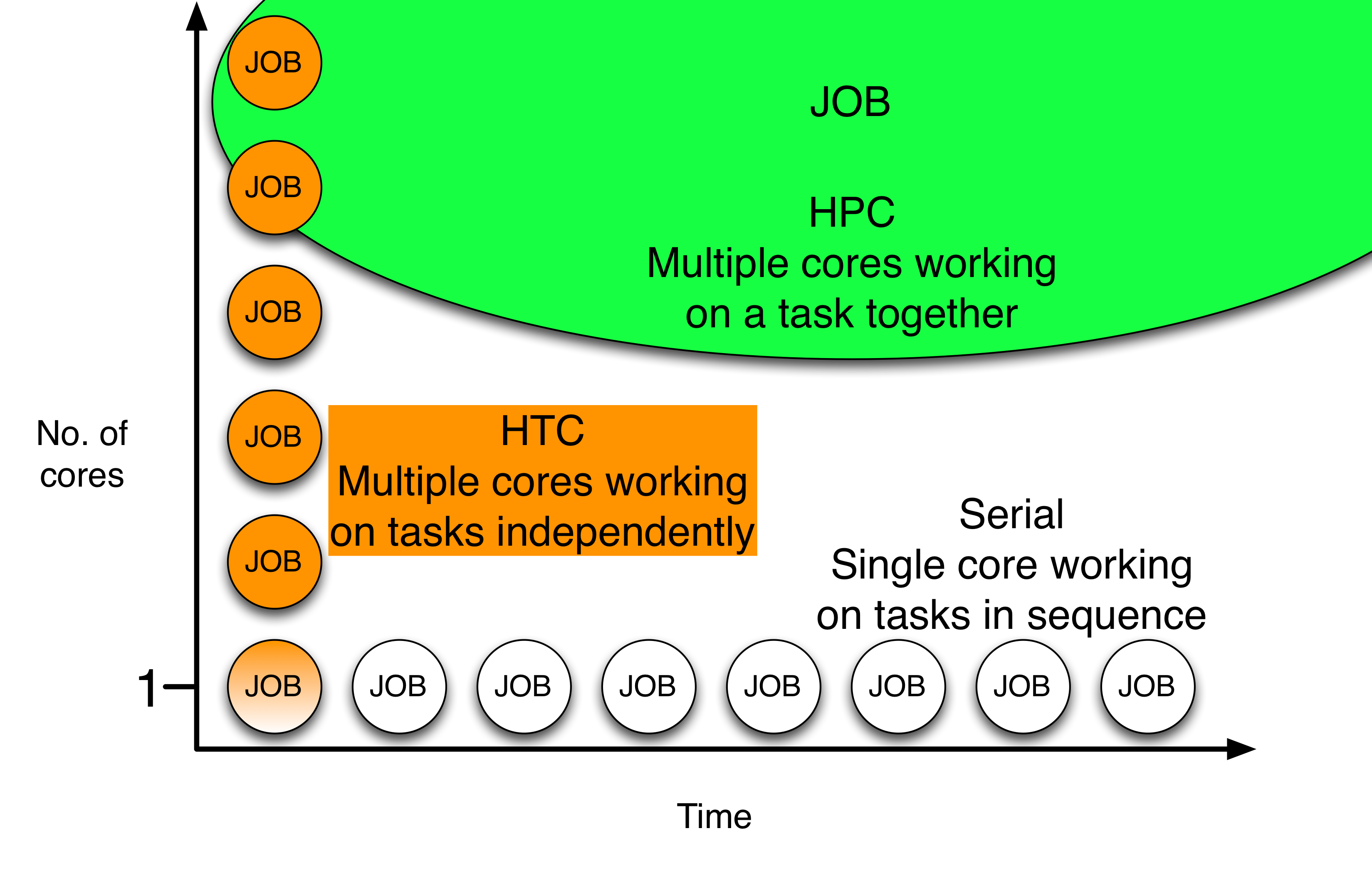
The HTCondor submit file keyword queue can run multiple jobs from a single job description file. In this tutorial, we will see how to scale up the calculations for a simple Python example using the queue keyword.
Once we understand the basic HTCondor script to run a single job, it is easy to scale up.
You can get the example files via the tutorial command,
$ tutorial ScalingUp-Python
$ cd tutorial-ScalingUp-Python
The tutorial-ScalingUp-Python directory contains all the required files. This includes the sample Python program, job description file, and executable files.
Python Script
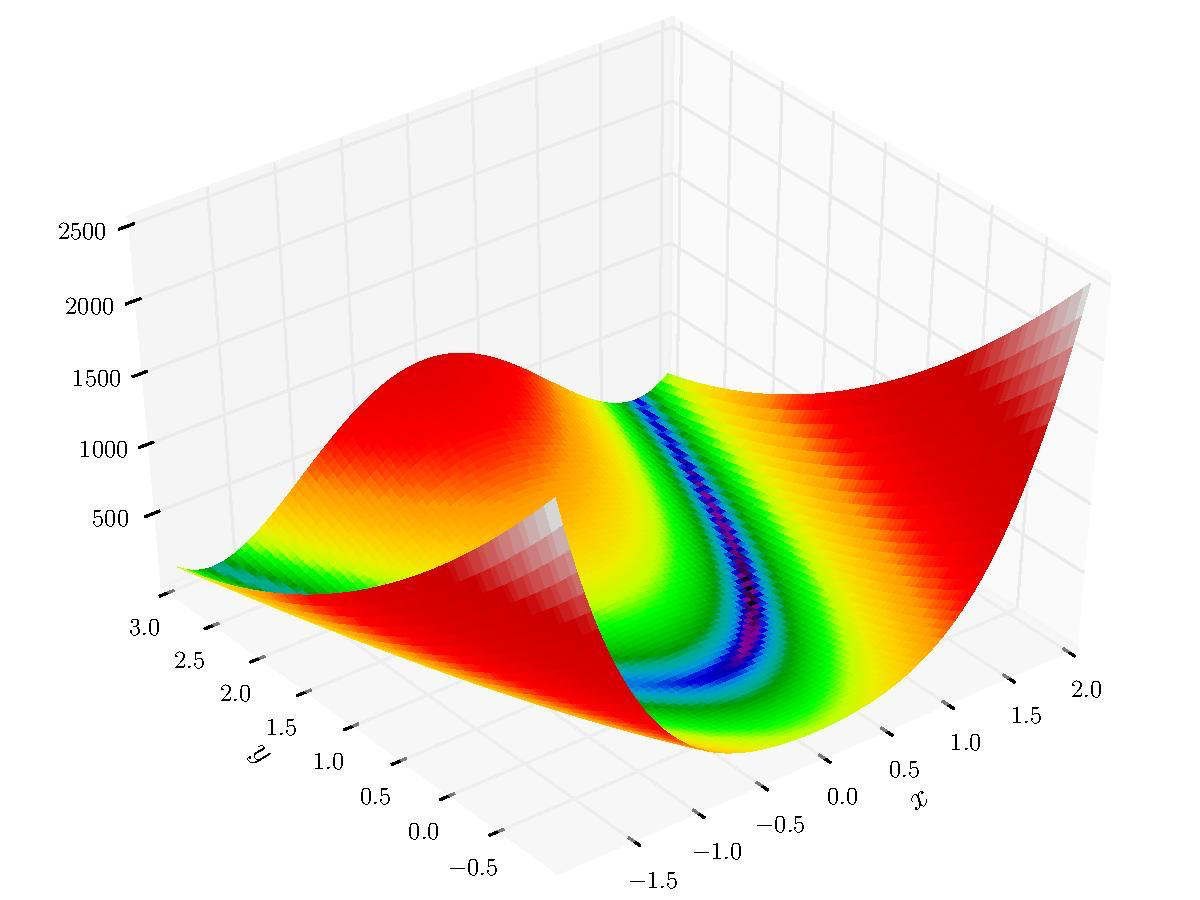
Here, we are going to use a brute force approach to finding the minimum/maximum (also known as "optimiziation") of a two dimensional function on a grid of points. Let us take a look at the function (also known as the objective function) that we are trying to optimize:
f = (1 - x)**2 + (y - x**2)**2
This is the two dimensional Rosenbrock function, which is used to test the robustness of an optimization method.
By default, Python script will randomly select the boundary values of the grid that the optimization procedure will scan over. These values can be overridden by user supplied values.
To run the calculation with random boundary values, the script is executed without any argument
$ module load python/3.4
$ module load all-pkgs
$ python rosen_brock_brute_opt.py
To run the calculation with the user-supplied boundary values, the script is executed with input arguments
python rosen_brock_brute_opt.py x_low x_high y_low y_high
where x_low and x_high are low and high values along x-direction, and y_low and y_high are the low and high values along the y-direction.
For example, to set the boundary in the x-direction as (-3, 3) and the boundary in the y-direction as (-2, 2), run
$ python rosen_brock_brute_opt.py -3 3 -2 2
The directory Example1 runs the Python script with the default random values. The directories Example2, Example3 and Example4 deal with supplying the boundary values as input arguments.
Execution Script
Let us take a look at the execution script, cat scalingup-python-wrapper.sh
#!/bin/bash
module load python/3.4
module load all-pkgs
python ./rosen_brock_brute_opt.py $1 $2 $3 $4
The wrapper loads the the relevant modules and then executes the python script rosen_brock_brute_opt.py. The python script takes four optional arguments.
Submitting Set of Jobs with Single Submit File
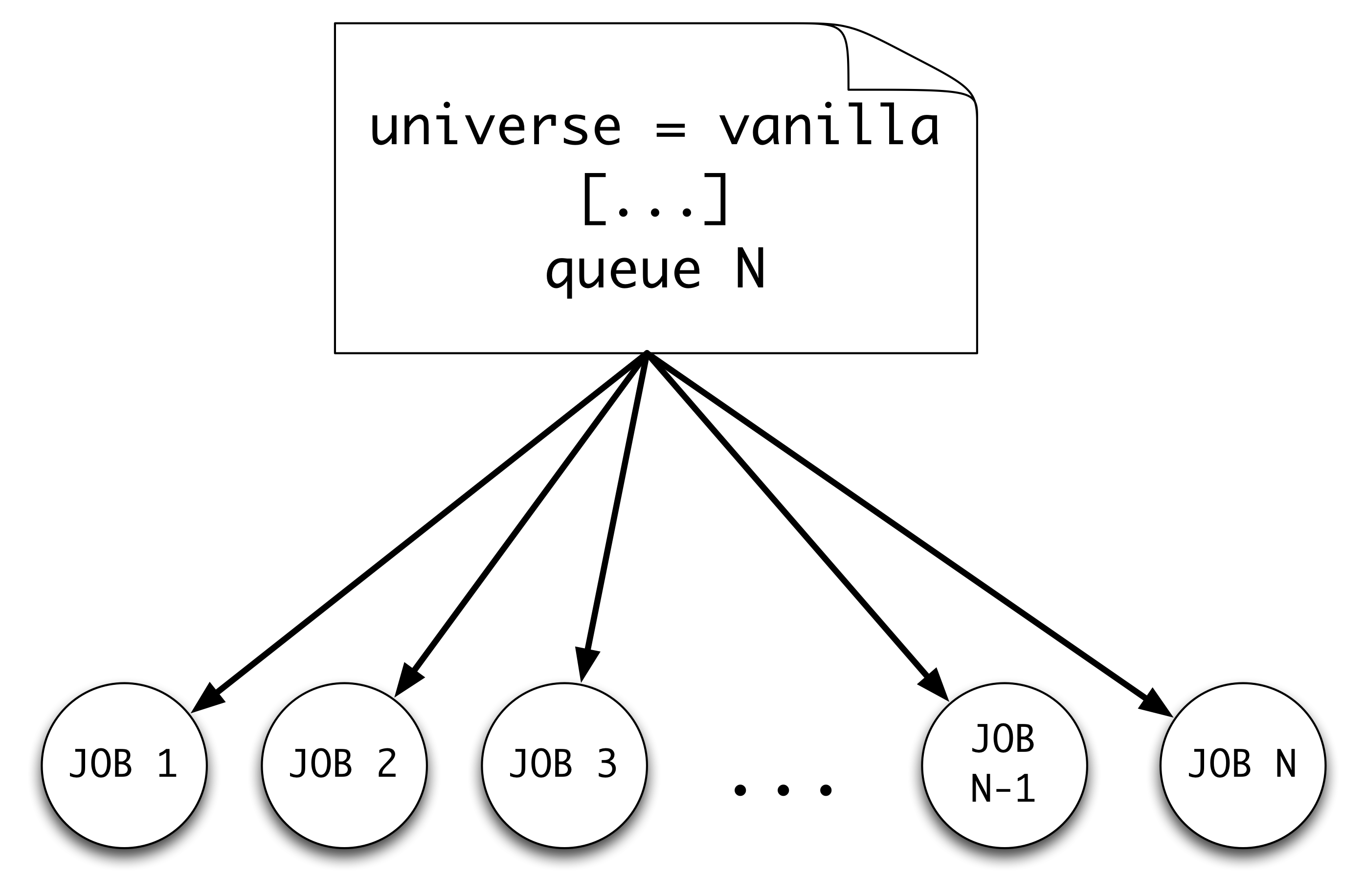
Now let us take a look at job description file
$ cd Example1
$ cat ScalingUp-PythonCals.submit
If we want to submit several jobs, we need to track log, out and error files for each job. An easy way to do this is to add the $(Cluster) and $(Process) variables to the file names.
# The UNIVERSE defines an execution environment. You will almost always use VANILLA.
Universe = vanilla
# These are good base requirements for your jobs on the OSG. It is specific on OS and
# OS version, core, and memory, and wants to use the software modules.
Requirements = OSGVO_OS_STRING == "RHEL 6" && TARGET.Arch == "X86_64" && HAS_MODULES == True
request_cpus = 1
request_memory = 1 GB
# executable is the program your job will run
# It's often useful to create a shell script to "wrap" your actual work.
executable = ../scalingup-python-wrapper.sh
# files transferred into the job sandbox
transfer_input_files = ../rosen_brock_brute_opt.py
# error and output are the error and output channels from your job
# that HTCondor returns from the remote host.
output = Log/job.out.$(Cluster).$(Process)
error = Log/job.error.$(Cluster).$(Process)
# The log file is where HTCondor places information about your
# job's status, success, and resource consumption.
log = Log/job.log.$(Cluster).$(Process)
# Send the job to Held state on failure.
on_exit_hold = (ExitBySignal == True) || (ExitCode != 0)
# Periodically retry the jobs every 60 seconds, up to a maximum of 5 retries.
# The RANDOM_INTEGER(60, 600, 120) means random integers are generated between
# 60 and 600 seconds with a step size of 120 seconds. The failed jobs are
# randomly released with a spread of 1-10 minutes. Releasing multiple jobs at
# the same time causes stress for the login node, so the random spread is a
# good approach to periodically release the failed jobs.
PeriodicRelease = ( (CurrentTime - EnteredCurrentStatus) > $RANDOM_INTEGER(60, 600, 120) ) && ((NumJobStarts < 5))
# Queue is the "start button" - it launches any jobs that have been
# specified thus far.
queue 10
Note the queue 10. This tells HTCondor to queue 10 copies of this job under one cluster id.
Let us submit the above job
$ condor_submit ScalingUp-PythonCals.submit
Submitting job(s)..........
10 job(s) submitted to cluster 329837.
Apply your condor_q and watch (watch -n2 condor_q $USER) knowledge to see this job progress . After all jobs finished, execute the post_process.sh script to sort the results.
./post_process.sh
Variable Expansion via queue Keyword
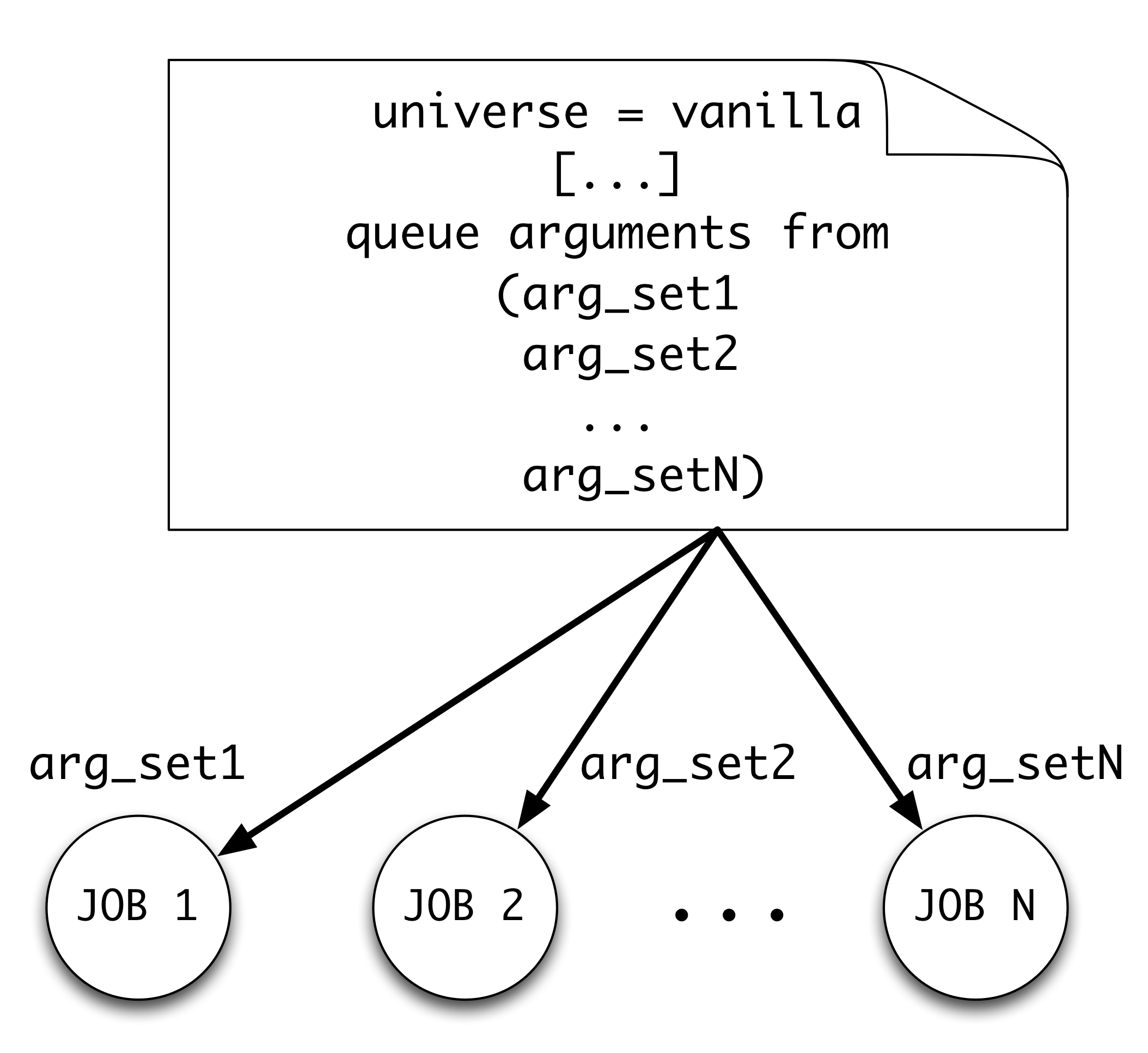
In the previous example, we did not pass any argument to the program and it used randomly-generated boundary conditions. If we have some idea about where the minimum/maximum is, we can supply boundary conditions to the calculation through arguments. To get a better idea of what are good boundary conditions, we want to scan over a number of boundary parameter sets. The queue command allows us to submit a job for each possible boundary condition we want to test using a single submit file.
Take a look at the job description file in Example3.
$ cd ../Example3
$ cat ScalingUp-PythonCals.submit
[...]
queue arguments from (
-9 9 -9 9
-8 8 -8 8
-7 7 -7 7
-6 6 -6 6
-5 5 -5 5
-4 4 -4 4
-3 3 -3 3
-2 2 -2 2
-1 1 -1 1
)
Let us submit the above job
$ condor_submit ScalingUp-PythonCals.submit
Submitting job(s)..........
9 job(s) submitted to cluster 329839.
Apply your condor_q and watch knowledge to see this job progress. After all jobs finished, execute the post_process.sh script to sort the results.
./post_process.sh
In fact, we could define variables and assign them to HTCondor's expression. This is illustrated in Example 4.
$ cd ../Example4
$ cat ScalingUp-PythonCals.submit
[...]
arguments = $(x_low) $(x_high) $(y_low) $(y_high)
# Queue keyword
queue x_low x_high y_low y_high from (
-9 9 -9 9
-8 8 -8 8
-7 7 -7 7
-6 6 -6 6
-5 5 -5 5
-4 4 -4 4
-3 3 -3 3
-2 2 -2 2
-1 1 -1 1
)
The queue command defines the variables x_low, x_high, y_low, and y_high. These variables are passed on to the argument command (arguments = $(x_low) $(x_high) $(y_low) $(y_high)).
Let us submit the above job
$ condor_submit ScalingUp-PythonCals.submit
Submitting job(s)..........
9 job(s) submitted to cluster 329840.
Apply your condor_q and watch knowledge to see this job progress. After all jobs finished, execute the post_process.sh script to sort the results.
./post_process.sh
Beyond the queue Keyword
For larger workloads, with more than 100 jobs or job interdependencies, there are a couple tools (DAGMan and Pegasus) that we recommend using. They are beyond the scope of this tutorial. Please contact our support staff for more details.